スマート工場構築のリーダー大韓エフエーシステムの絶え間ない挑戦は続きます。
製品紹介
- 製品概要
- 製品仕様
- 適用例

- MCCS
- 今日のミッション/ビジネス・クリティカルな環境では、アプリケーションサービスは、中断することなく動作する必要があります。つまり、障害によるサービスのダウンタイムはビジネスの損失に連結され、これ以上の許容されてはいけません。MCCSは、サーバー、アプリケーションサービス、ネットワーク、ストレージだけでなく、システムリソースとアプリケーションリソースの問題に起因する障害に対してサービス継続性を確保し、可用性を最大化することができるソリューションです。MCCSは、自動障害処理とリアルタイムのデータ複製を介してミッション/ビジネス・クリティカルなアプリケーションを24 x 7 x 365日、運営することができます。 また、重要なイベント発生時SMSアラームを介して障害の緊急連絡とフォローアップを迅速に行うことができます。
-
- サーバーのクラスタ化
- MCCSは、サーバーのハードウェア、ソフトウェア、ネットワーク、ストレージなどの障害の種類に関係なく 、すべてのアプリケーションを24 x 7 x 365日、運営することができます。MCCSは、すべてのアプリケーションの種類に対して保護が可能であり、サーバークラスタリングによって、ダウンタイムを数分から数秒に最小化します。
-
- リアルタイムブロック複製
- ブロックレベル複製でターゲットとソースのデータ整合性を保証します。両方のサーバー間でデータの複製モジュ ールが構成されれば、ソースボリュームへの書き込みが発生したとき、TCP / IPネットワークを介して、ターゲットボリュームに同時に書き込みを行うことになります。MCCSは、あらゆる種類のファイルとデ ータベースをサポートし、障害や災害に対して、重要なデータが失われません。
-

- グローバルダッシュボード
- クラウドベースのグローバル管理センターを介して複数の分散したクラスタを一目で管理することができます。また、可用性レポートを使用して、可用性に関する統計情報を直感的に見ることができます。
主な機能
| 機能 | 詳細機能 | |
|---|---|---|
| 障害検出と自動切替 | アプリケーション |
|
| ディスクI / O |
|
|
| ネットワーク |
|
|
| データのリアルタイム複製 |
|
|
| Split Brain防止 |
|
|
| 障害通知 |
|
|
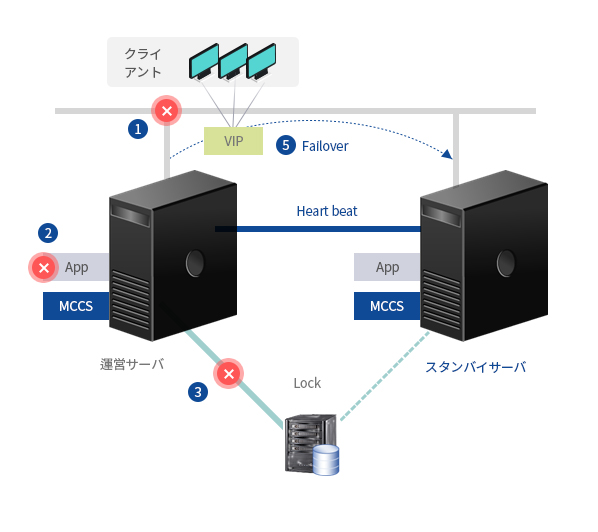
- 1. 運営サーバーのネットワーク障害検出
- 2. 運営サーバーのアプリケーションの障害を検出
- 3. 共有ストレージディスクI / O障害の検出
- 4. 障害の検出時に、既存のサーバーで再起動(ユーザー設定)
- 5. 再起動後に障害が発生し、スタンバイサーバーに自動的切替 EMSで障害内容文字通報
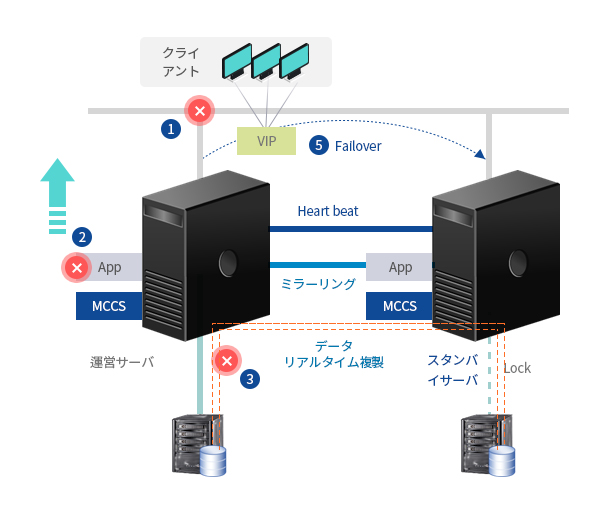
運営サーバーのストレージデータをスタンバイサーバのストレージに リアルタイム複製(同期化)
- 1. 運営サーバーのネットワーク障害検出
- 2. 運営サーバーのアプリケーションの障害を検出
- 3. 運営ストレージディスクI / O障害の検出
- 4. 障害の検出時に、既存のサーバーで再起動(ユーザー設定)
- 5. 再起動後に障害が発生し、スタンバイサーバーに自動的切替 EMSで障害内容文字通報
お客様の環境に合わせて、さまざまな構成方式
- 外装共有
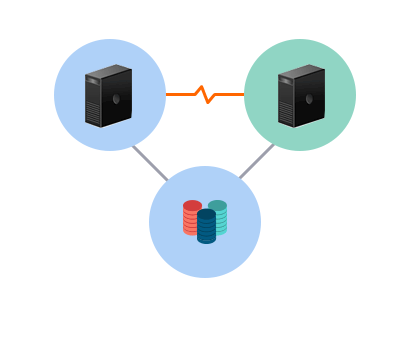
- サーバー間の複製
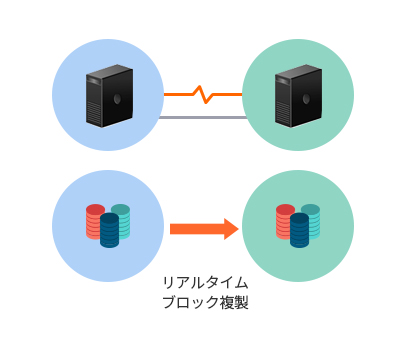
- 遠隔地の災害復旧
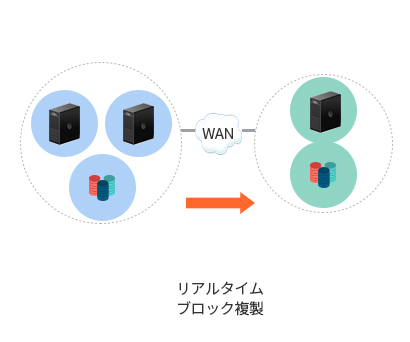
- P – to - P

- P – to - V
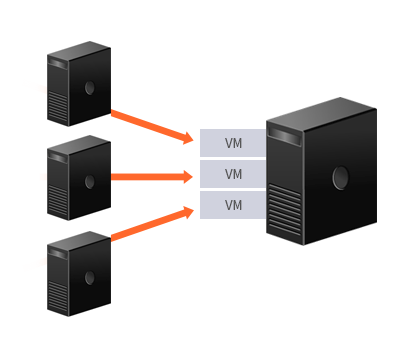
- V – to - V
