The constant challenge for the KFA,the leader of the Smart Factory, continues.
Products
- Overview
- Specification
- Example

- MCCS
- In today’s mission/business-critical environments, application services need uninterrupted operations. Service downtime caused by failure is no longer acceptable. MCCS is designed to solve problems and protect your critical applications against hardware and software failures (covering your servers, application services, networks, and storage devices) , as well as failures caused by system and application resource issues. MCCS keeps your mission/business critical applications running 24 x 7 x 365 days with automatic failover and real time data replication. It also provides SMS alarms for fast notification of critical events.
-
- Server Clustering
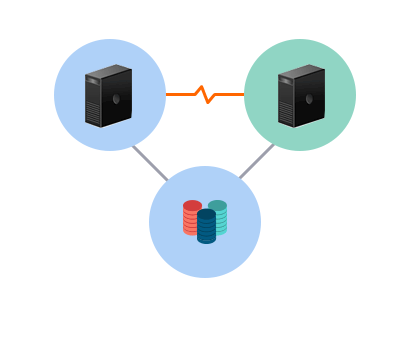
- MCCS ensures all applications are available 24 x 7 x 365 days regardless whether the failure is related to server hardware, software, networks or storage. MCCS protection is not limited to 'cluster aware' application, but covers all types. Through server clustering, downtime is minimized to minutes and even seconds.
-
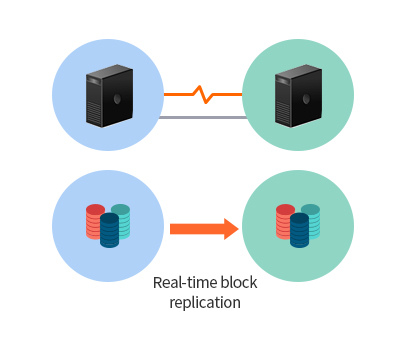
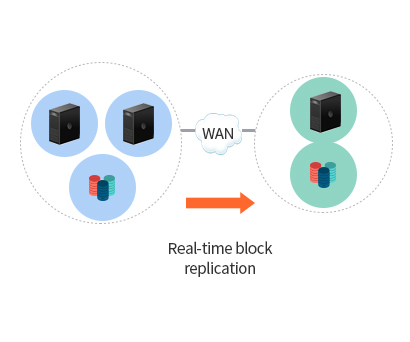
- Real-time block replication
- Block level replication ensures target data is identical it’s source. When mirror is established between two server, MCCS intercepts all writes to the source volume and replicates that across the TCP/IP network to the target volume simultaneously. It also supports all types of files and DBMS. With this, you will not lose your mission-critical data to failure and disaster.
-

- Global dashboard
- MCCS bundles a Global Management Center in the Enterprise and Virtual editions, and via the cloud for MCCS Workgroup Edition. In a single view, you can manage all clustered servers and availability reporting.
Function
| Function | Detail Function | |
|---|---|---|
| Fault detection and Auto-switching | Applications |
|
| Disk I/O |
|
|
| Network |
|
|
| Real-time data replication |
|
|
| Split Brain Prevention |
|
|
| Notification of failure |
|
|
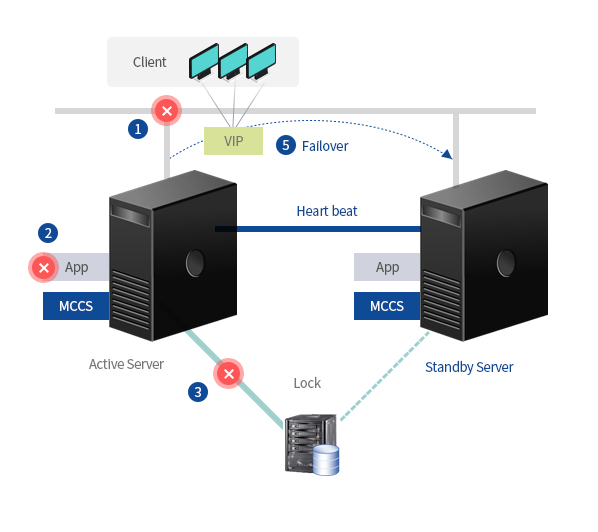
- 1. Detect network failure of Active server
- 2. Detect applications failure of Active server
- 3. Detect failure of shared storage disk I/O
- 4. Restart from existing server when failure is detected(User set up)
- 5. Automatically switch to standby server if a failure occurs even after restart and send fault history as SMS
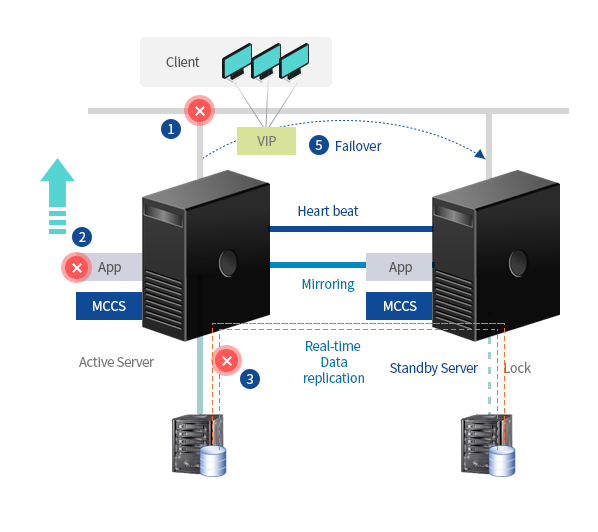
Real-time replication(synchronization) of storage data from Active server to storage on standby server
- 1. Detect network failure of Active server
- 2. Detect applications failure of Active server
- 3. Detect failure of Active server’s storage disk I/O
- 4. Restart from existing server when failure is detected(User set up)
- 5. Automatically switch to standby server if a failure occurs even after restart and send fault history as SMS
Various configurations according to customer's environment
- External shared storage
- Server-to-server replication
- Remote disaster recovery
- P – to - P

- P – to - V
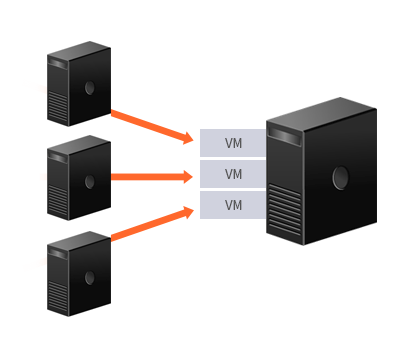
- V – to - V
